[CKA] 쿠버네티스 Pod | 스케줄링

본 글은 Udemy Certified Kubernetes Administrator (CKA) 강의를 참조해 정리한 내용을 기록했습니다.
Label & Selector
Kubernetes에는 다양한 리소스가 존재하고 이를 구별하기 위해 그룹화를 하는데 이런 그룹화를 위한 개념
Label은 특정 Pod, Node, Service를 구분하고, Selector를 통해 특정 Label을 가진 리소스를 선택한다.
Label
리소스에 Key-Value 형태로 추가 가능한 메타데이터로 그룹화를 사용하는데 있어 기본적으로 사용된다.
1
2
3
4
5
6
7
8
9
10
11
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
app: my-app
env: production
spec:
containers:
- name: nginx
image: nginx
이 Pod는 my-app 이라는 앱에 속해 있으며, 운영 환경은 production 영역에서 작동한다.
이러한 정보 이외에도 key와 Value는 원하는대로 설정이 가능한데 tier=backend 등등… 이러한 Label의 변화는 리소스를 재시작 하지 않아도 영향에 끼친다.
Selector
Label을 통해 리소를 그룹화 했다면 Selector를 통해 리소스를 선택할 수 있다.
주로 Service, Deployment, ReplicaSet등이 Pod를 선택한다.
Service에서 pod를 연결하기
1
2
3
4
5
6
7
8
9
10
11
12
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app # app=my-app 라벨이 있는 파드와 연결됨
ports:
- protocol: TCP
port: 80
targetPort: 80
Deployment에서 Pod를 연결하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
app: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app # Selector와 일치해야 함
spec:
containers:
- name: nginx
image: nginx
해당 Deployment는 두 개의 metedata를 보유하고 있는데 template.metadata. 같은 경우 생성되는 Pod에 대한 metada로 관리 되며 my-app 으로 붙여진 pod만 selector 를 통해 관리한다
Resource Requirements and Limits
k8s에서는 pod의 CPU와 메모리를 설정하여 pod가 실제 사용할 수 있는 리소스를 제어할 수 있다.
이는 Request와 Limit으로 설정되며 Request는 Pod가 구성되기 위한 최소한으로 보장받는 리소스를 뜻하며, Limit은 Pod가 사용할 수 있는 최대 리소스의 제한을 뜻한다. kube-scheuler는 이러한 정보를 기반으로 Request가 적절하게 요구되는 node로 Pod를 스케줄링한다.
CPU & Memory 단위
| 리소스 | 단위 | 예제 |
|---|---|---|
| CPU | m (milliCPU) | 500m = 0.5 vCPU (코어) |
| 메모리 | Mi, Gi | 512Mi = 512MB, 1Gi = 1GB |
그렇다면 Request와 Limit을 어떤식으로 설정을 해야할까?
Request만 보장
1
2
3
4
5
6
7
8
spec:
containers:
- name: my-app
image: my-image
resources:
requests:
memory: "256Mi" # 최소 256Mi 메모리 보장
cpu: "250m" # 최소 0.25 vCPU 보장
kube-scheduler에게 request를 기준으로 적절한 Pod에 배치해달라고 공지한다.
Limit만 보장
1
2
3
4
5
6
7
8
9
10
11
spec:
containers:
- name: my-app
image: my-image
resources:
requests:
cpu: "250m" # 최소 0.25 vCPU 보장
memory: "256Mi" # 최소 256Mi 보장
limits:
cpu: "500m" # 최대 0.5 vCPU 사용 제한
memory: "512Mi" # 최대 512Mi 사용 제한
적절한 Pod에 배치하고 그곳에서 사용량을 제한한다.
이럴 경우 만약 limits를 초과하게 된다면 CPU의 경우 이 이상 자원을 할당받지 못하기에 시스템이 느려지는 등 영향을 끼친다. (Pod가 죽지는 않음)
하지만 Memory가 초과시 처음에는 지속적으로 할당이 되지만 일정량을 초과하면 OOM이 발생하며 pod가 죽는다!
즉.. 서비스 자원을 최적화하는 것도 중요하지만 Limit은 적절하게 설정하여 pod가 죽어 서비스가 다운되는 현상이 발생하지 않게 해야한다.
DaemonSet
모든 Node에 1개씩의 Pod의 실행을 보장하는 컨트롤러로 Node가 추가될 경우 해당 Node에 Pod를 자동으로 하나 배포 한다.
이는 주로 클러스터 전체에서 로그를 수집하거나 모니터링을 사용하는데 주로 사용된다.
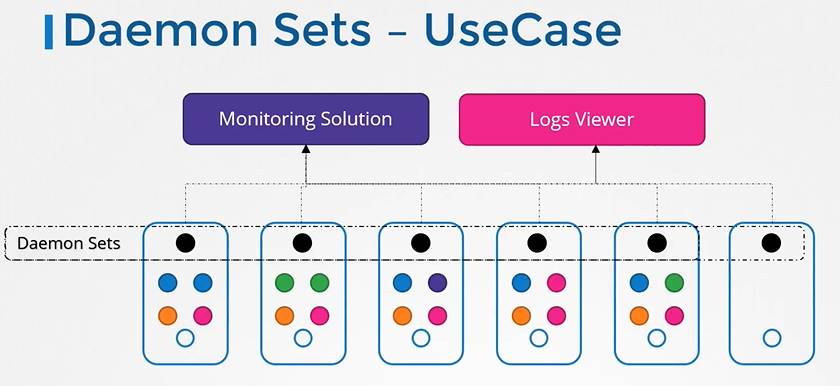 모니터링과 logger로 사용되는 daemonset
모니터링과 logger로 사용되는 daemonset
또한 kube-proxy 같은 자주 사용되는 pod 또한 daemonset 형식으로 관리되어진다.
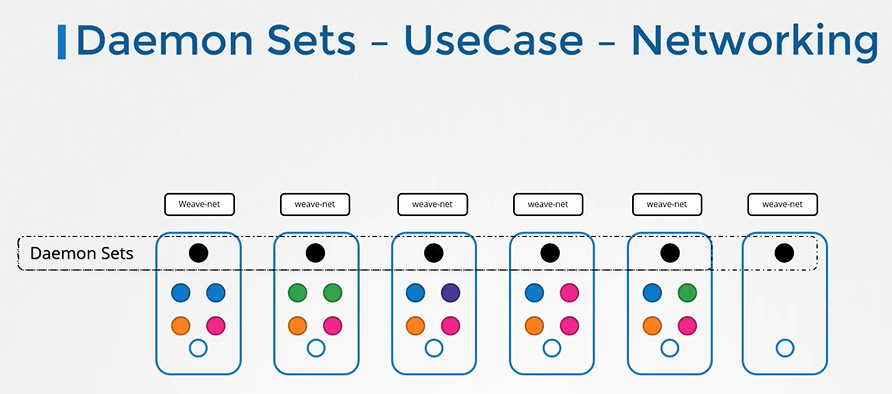 kube-proxy는 실제로 특정 pod에서만 실행된다.
kube-proxy는 실제로 특정 pod에서만 실행된다.
DeamonSet 만들어보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: busybox-daemon
labels:
app: busybox
spec:
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- name: busybox-container
image: busybox
command: ["sleep", "10000"]
이 DaemonSet은 모든 node에서 실행된다.
이렇게 배포된 deamonSet을 확인하기 위해서는 get 명령어를 사용한다.
1
kubectl get daemonset -A
-A옵션은--all-namespaces와 같은 의미로 모든 namespaces의 pod를 가져오는데 사용된다.
DeamonSet이 특정 node에만 있으면 좋겠어요
모든 node에 pod의 실행을 보장하는건 강력하지만 때로는 자원의 낭비를 초래할 수 있다. 그렇기에 label을 이용해 특정 node에만 DaemonSet를 사용할 수 있다.
우선 Deamonset의 label에 value를 설정한다.
1
2
3
4
5
spec:
template:
spec:
nodeSelector:
dedicated: monitoring
그리고 node에 kubectl label nodes <노드이름> dedicated=monitoring 를 설정하면 해당 value를 설정한 Node에만 pod가 실행되는 것을 확인 할 수 있다.
Static Pods
static pod란 node의 kubelet에 직접 실행되는 pod로, kube-api 에 의해 관리되지 않는 Node에서 직접 실행되는 pod이다.
클러스터(kube-api)가 관리하지 않기에 kubectl delete pod 명령어로 삭제할 수 없다. 하지만 read 를 사용하는 kubectl get pods 에서는 관측된다.
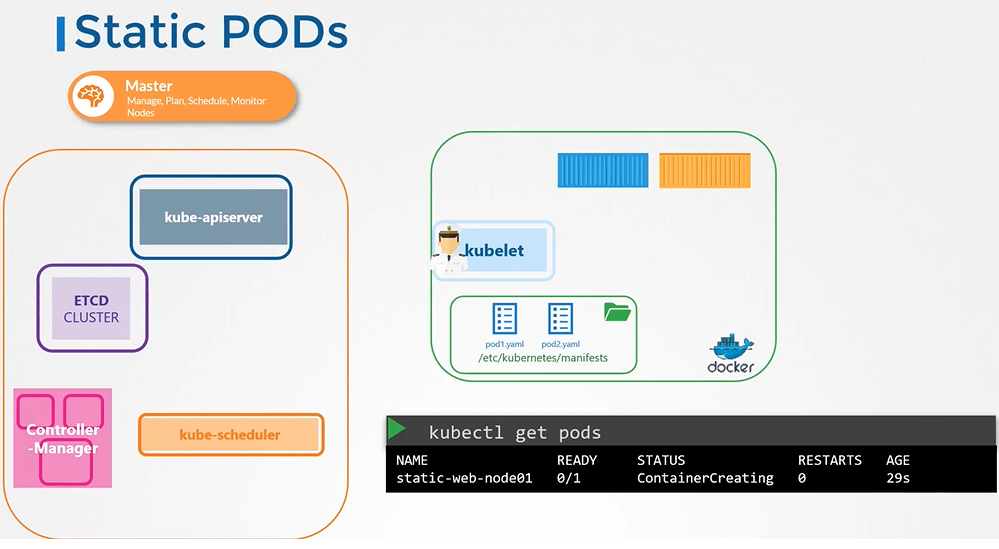
어떻게 생성하지?
cd /etc/kubernetes/manifests 로 디렉터리를 이동한다. 그곳에는 이미 ETCD나 kube-api 같은 static pods의 yaml이 있으며 그곳에 직접 YAML을 생성하면 자동으로 배포가 된다.
만약 내가 만든 static pods이 정상적으로 배포가 된 것을 확인 할려면 모든 namespaces에 대해 get을 하면 된다.
1
kubectl get pods --all-namespaces
삭제 할경우 해당 YAML을 제거하면 된다.
왜 사용하지?
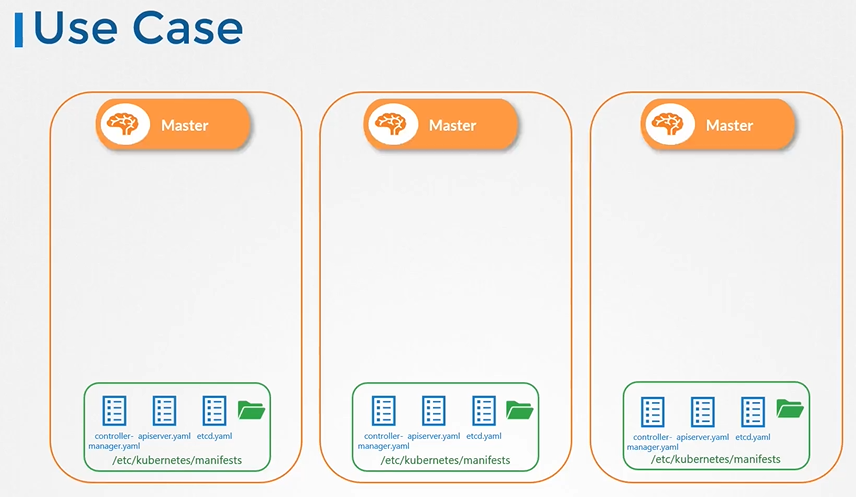
Master Node에는 지속적으로 있어야할 k8s 관리 pod들이 존재한다.
이러한 pod들을 static pods로 설정함으로써 별도의 배포 없이 관리 pod들이 기동되어진다.
DaemonSet vs Static Pod
kube-api가 관리하는 DaemonSet과 kubelet이 직접 관리하는 Static Pods의 경우는 비슷한 요구사항을 만족하는데 사용할 수 있지만 적절하게 사용하면 더 큰 효율을 볼 수 있다.
DaemonSet 같은 경우 kube-api가 관리해주기에 관리가 편하며 label을 통해 조건을 쉽게 조절할 수 있다. 그렇기에 로그 수집, 모니터링 같은 요구사항에 더 적합하다.
Static Pod의 같은 경우 Node에 직접 yaml을 통해 배포되기에 클러스터의 핵심 컴포넌트를 배포할 때 적절하게 사용되어진다. (클러스터가 초기화 되어도 자동으로 실행됨)
Manual Scheduling
앞서 배운 kube-scheduler는 자동으로 pod를 적절한 노드에 배치한다.
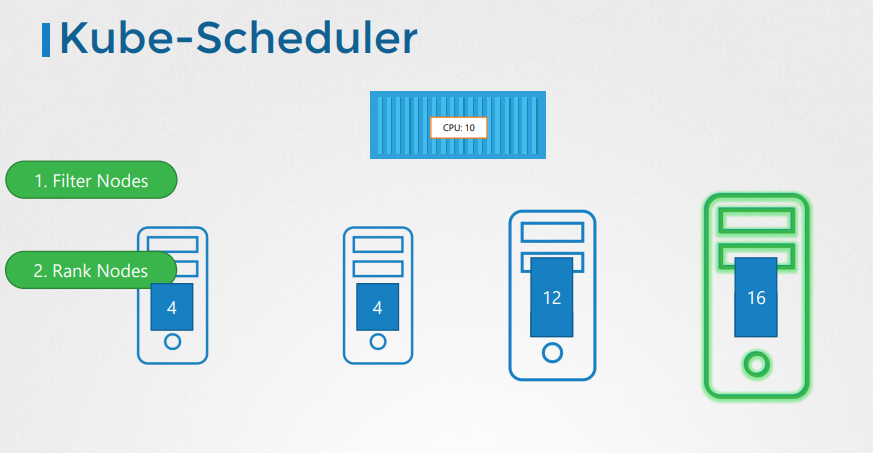
어떤 Node가 적합한지 점수를 측정해 판단하는 kube-scheduler
하지만 실제 운영 환경 구축을 위해 어떠한 Node가 정상적으로 해당 Pod를 실행할 수 있는지 또는 Node↔Pod에 있어 호환성 등을 테스트 하기 위해 특정 Node에 Pod를 수동으로 배치하는 디버깅 목적으로 필요할 수 있다.
이럴 때 사용되는 것이 Manual Scheduling으로 kube-scheduler로 인해 배치하지 않고 사용자가 직접 Node를 선택해야한다.
이때 사용할 Node는 nodeName 으로 지정한다.
Manual Scheduling을 사용는 경우 YAML
1
2
3
4
5
6
7
8
9
apiVersion: v1
kind: Pod
metadata:
name: manually-scheduled-pod
spec:
nodeName: worker-node-1 # 특정 노드에 직접 할당
containers:
- name: nginx
image: nginx
이렇게 Node를 직접 이름으로 지정하는 방법 이외에도 k8s는 다양한 방법을 지원한다. 아래에서는 어떤식으로 k8s에서 pod의 Node 할당을 제어하는지 알아보겠다.
Taints & Tolerations
Taints는 오염 이라는 뜻을 가지고 Tolerations는 관용이라는 뜻을 가진다. 왜 쿠버네티스를 공부하는데 이러한 개념에 굳이 이러한 명칭을 가지는지는 잘 모르겠지만 이러한 개념들은 특정 Taints(오염) 된 Node에 Toleration(관용)되지 않은 Pod가 들어가지 않게 하는… 조금 더 쉽게 표현하자면 특정 Node에 Pod rule을 추가하는 것으로 의미할 수 있겠다.
이제부터 이러한 오염과 관용을 어떤식으로 제어할 수 있는지 알아보도록 하겠다.
Taints를 Node에 적용하기
taints를 적용하기 위해서는 Node에 명령줄을 추가 하여 적용하는다 일반적인 형식은 아래와 같다.
1
kubectl taint nodes <노드명> <키>=<값>:<효과>
일반적으로 키:값 형태로 매핑을 하고 이와 같은 Node가 있을 경우 <효과> 의 형태를 가지게 설정한다.
Tolerations를 Pod에 적용하기
더렵혀진 Node(taintsed Node)에 할당 되기 위해서는 pod의 spec 에 아래와 같은 toleration항목을 추가해줘야한다.
1
2
3
4
5
tolerations:
- key: "<키>"
operator: "Equal" # 또는 "Exists"
value: "<값>"
effect: "<효과>"
여기서 operator는 Equal 또는 Exists를 사용할 수 있으며, 각각 키와 값이 일치하거나 키만 존재하는 경우를 의미한다.
Taint가 Blue이고 Node의 Value에 Blue를 설정 한 경우
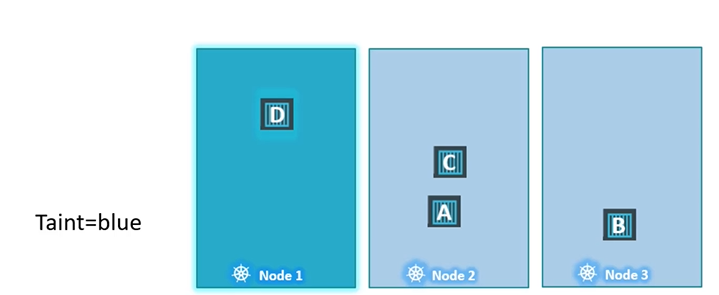
kube-scheduler는 Key=blue 가 아닌 Pod은 Node1에 할당하지 않고 tolerations가 blue인 Pod D만 Node1에 할당 한 것을 볼 수 있다.
이걸 왜 쓰는거지?
작업을 하다보면 특정 워크로드를 Node에 설정할 때가 있다. 예를 들어 데이터베이스 수정 같은 작업을 특정 노드에서만 할당 했다면 이 작업을 시작할 Pod는 toleration을 설정이 가능하다.
또한 이외에도 Node를 유지보수 한다거나(디버깅), 특정 Pod를 격리 시킬 때 이러한 개념을 사용할 수 있다.
Node Selector
pod는 별다른 제약이 없는한 어떠한 Node로도 할당 될 수 있다. 만약 Node간의 성능이 다르고 사양이 높은 pod가 저 사양의 Node에 할당이 된다면 서비스 운영에 제약이 발생할 수 있다.
이를 제한하기 위해 nodeSelector라는 개념을 사용해서 Key-Value 형식으로 어떠한 Node에 pod를 고정할지 지정이 가능하다.

일반적으로 Node에 label을 붙이기 위해서는 아래와 같은 형식을 따른다.
1
kubectl label nodes <node-name> <label-key>=<label-value>
예시
1
kubectl label nodes node-1 size=Large
이러한 방식은 간단하고 쉽게 도달되지만 더 높은 요구사항을 높이기 위해 Node Affinity라는 개념이 등장한다.
Node Aiffinity
label 기반 스케줄링 결정에 있어 강력한 효과를 낸다. 기존의 Node Selector에 비해 표현식(expression)을 사용해 더 복잡한 규칙을 만들 수 있다.
예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: zone
operator: In
values:
- us-east1
requiredDuringSchedulingIgnoredDuringExecution(필수 규칙)pod가 스케줄링 되어질 때 반드시 해당하는 규칙의 Node에만 할당된다.
위의 예제에서는
disktype**이ssd인 node에만 스케줄링이 되도록 지정한다.preferredDuringSchedulingIgnoredDuringExecution(선호 규칙)pod에 이러한 규칙이 우선적으로 적용되지만 반드시 만족하지 않아도 할당된다.
zone이us-east1인 node를 우선적으로 선호한다.Operator (연산자)
In: 지정한 값 중 하나와 일치NotIn: 지정한 값 중 어느 것도 일치하면 안된다.Exists: 지정한 Key가 Node에 존재해야 한다.DoesNotExist: 지정된 Key가 Node에 없어야한다.
Node Affinity의 동작 방식은 Pod가 스케줄링 될 때에만 적용된다는 것을 명심하자. 즉 Pod가 한번 Node에 배치가 된다면 label 이 변경되더라도 Pod는 지속적으로 실행된다. 또한 이러한 규칙의 우선순위에 따라 스케줄링 방식이 꼬일 수 있음을 인지하고 요구 사항에 맞게 적절하게 조합해야 한다.
Taints & Tolerations vs Node Affinity
해당 개념들은 모두 Pod의 스케줄링을 제어하는 기능으로 각자 다른 방식으로 동작한다.
Taints & Tolerations
- 특정 Node에서 Pod를 거부하거나 허용함
Node Affinity
- Pod의 배치에 있어 선호도를 사용 가능
- Label을 통해 제한함
일반적으로 Taints & Tolerations는 특정 Node에서 Pod를 퇴출하는데 사용되고 Node에 특정 Pod를 배치하는데는 Node Affinity가 선호된다.
Multiple Schedulers
kube-scheduler가 Node에 pod를 할당시키지만 하나 이상의 스케줄러도 실행할 수 있다! 또한 pod의 yaml에 spec.schedulerName 필드를 사용하면 특정 스케줄러를 고를 수 도 있다.
pod에서 특정 scheduler를 지정
1
2
3
4
5
6
7
8
9
apiVersion: v1
kind: Pod
metadata:
name: nginx-custom
spec:
schedulerName: my-scheduler
containers:
- name: nginx
image: nginx
my-scheduler를 만드는 방법은 기본으로 존재한 kube-scheduler를 복사하여 만들 수가 있다.
기존의 yml을 복사하여 수정하는 방법
1
sudo cp /etc/kubernetes/manifests/kube-scheduler.yaml /etc/kubernetes/manifests/my-scheduler.yaml
이렇게 별도로 복사해서 아래와 같이 수정하면된다. 이렇게 해서 배포하면 kubelet은 이걸 static pod으로 감지하여 실행시킨다.
1
2
3
4
5
6
7
8
spec:
containers:
- command:
- kube-scheduler
- --scheduler-name=my-scheduler
- --leader-elect=false # 하나만 띄울 거면 이 옵션을 false로
- --config=/etc/kubernetes/scheduler-config.yaml
Admission Controller

get이나 create 명령을 수행하는데 있어, 이 요청을 검사 또는 수정하는 k8s 플러그인 중 하나이다. API Server 내부에서 실행되는 Admission Controller는 web hook을 통해 사용자의 요청을 검사(인증 또는 권한을 확인)하여 거부 또는 수정을 할 수 있다.
사용자가 요청을 명령을 요청할때 순서는 아래와 같다.
1
Client → API Server → Authentication → Authorization → Admission Controller → etcd 저장
여기서 Admission Controller는 리소스가 etcd에 저장되기전 최종 검증자 역할을 실행한다.
Admission Controller의 유형
Validating Admission Controller - 리소스를 유요한지 검증만
Mutating Admission Controller - 리소스를 검증하고 변경도 가능
이를 통해 외부 웹서버(WebHook)과 통신하여 요청을 조작 및 감시가 가능하다.