[K8s/JVM] Node부터 JVM의 Memory 관리
컨테이너 환경을 운영하다보면 가장 자주 발생하는 오류는 OOM(OutOfMemory)라고 생각됩니다. Java기반 Pod의 안정적인 운영을 위해서는 메모리 관리에 대한 지식이 필수적입니다.
그렇기에 K8s 영역과 JVM영역에 대한 이해가 필요하다고 생각되어, 실제 사례 기반과 함께 Node 영역에서부터 JVM까지 메모리 관리 방식에 대해 알아보겠습니다.
Kubernetes의 메모리 할당 법
기본적으로 Pod들은 Node 위에 올라가고 kubelet이라는 K8s Agent가 지속적으로 Node의 메모리 압박을 관리하고 있습니다.
Node 확인하기
1
2
3
C:\Users\>kubectl get node
NAME STATUS ROLES AGE VERSION
aks-userpool01-35617680-vmss000000 Ready <none> 224d v1.33.1
Node의 스펙 확인하기
kubectl describe를 통해 Node의 다양한 정보들을 확인할 수 있습니다.
다만 이번에는 여기서 자원 부분만 추출하여 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
C:\Users\>kubectl describe node aks-userpool01-35617680-vmss000000
Name: aks-userpool01-35617680-vmss000000
Roles: <none>
Labels: agentpool=userpool01
beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=Standard_D8s_v5
(... 생략)
Capacity:
cpu: 8
ephemeral-storage: 129886128Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32863208Ki
pods: 250
Allocatable:
cpu: 7820m
ephemeral-storage: 119703055367
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 27589608Ki
pods: 250
(... 생략)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
argocd argocd-argo-cd-dex-84988fb64b-sm2fm 100m (1%) 150m (1%) 128Mi (0%) 192Mi (0%) 55d
myservice my-pod-5448854566-9nwcw 200m (2%) 500m (6%) 500Mi (1%) 1000Mi (3%) 2d5h
kube-system microsoft-defender-collector-ds-msm7c 80m (1%) 360m (4%) 160Mi (0%) 296Mi (1%) 20d
kube-system microsoft-defender-publisher-ds-7n7tq 30m (0%) 60m (0%) 32Mi (0%) 200Mi (0%) 20d
kube-system retina-agent-bjl5z 100m (1%) 500m (6%) 200Mi (0%) 300Mi (1%) 40d
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1649m (21%) 6170m (78%)
memory 2862Mi (10%) 16432Mi (60%)
ephemeral-storage 50Mi (0%) 2Gi (1%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Node 자체의 memory 부분은 아래와 같습니다.
1
2
Capacity: 32863208Ki = ~31.3Gi (Node 실제 물리 메모리)
Allocatable: 27589608Ki = ~26.3Gi (K8s가 Pod에 할당 가능한 메모리)
Q. 왜 차이가 나나요?
A. OS, kubelet, 시스템 데몬이 약
5Gi를 미리 점유하기 때문입니다.
그리고 현재 할당량은 아래와 같습니다.
1
2
3
4
5
6
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1649m (21%) 6170m (78%)
memory 2862Mi (10%) 16432Mi (60%)
Requests: 현재 Pod들이requests수치를 통해 예약된 자원의 총합Limits: Pod에limits으로 설정한 자원의 총합
현재 Node의 메모리 사용량 보기
1
2
3
C:\Users\>kubectl top node aks-userpool01-35617680-vmss000000
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
aks-userpool01-35617680-vmss000000 144m 1% 8901Mi 33%
Node가 현재 사용하고 있는 자원을 볼 수 있습니다.
이를 통해 Node의 스펙, 할당된 자원, 실제 사용량을 확인하는 방법을 알아보았습니다.
Ex1. Node 부하 상태에서 Pod 기동 Case
requests는 Pod가 기동되기 위해 반드시 확보되어야 할 자원입니다.
아래와 같이 Node의 CPU가 과부하 상태라고 가정하겠습니다.
Node 스펙: CPU 5코어(5000m)
1
2
3
4
5
6
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 4649m (81%) 16170m (158%)
memory 2862Mi (10%) 16432Mi (60%)
현재 Requests 수치의 여유가 약 360m 정도 남은 Node입니다.
이때 아래의 Spec을 가진 Pod를 기동하려고 하면 자원이 부족하여 Pending 상태에 빠지게 됩니다.
1
2
3
4
5
6
7
resources:
requests:
cpu: 500m
memory: 1000Mi
limits:
cpu: 1000m
memory: 2000Mi
이럴 경우 아래와 같은 방법 중 가능한 방법을 선택해 해결할 수 있습니다.
- Node의 자원 확보
- Pod의
requests조절 replica수 조절
Ex2. limits 설정 누락된 채로 Pod 기동
K8s는 limits가 없으면 제한을 걸지 않습니다. 즉 Node의 자원을 무한하게 사용할 수 있습니다.
limit 설정이 없다면?
1
2
3
4
5
limits 없는 Pod가 메모리를 계속 사용
→ Node 전체 메모리 고갈
→ Node 레벨 OOM 발생
→ kubelet이 가장 우선순위 낮은 Pod를 Evict
→ 최악의 경우 Node 전체 불안정
Pod를 기동시킬 때는 자원의 limits 설정을 반드시하여 예상치 못한 동작에 대비해야합니다.
지금까지 Kubernetes의 메모리 할당 방식을 살펴보았습니다. 다음으로는 JVM 영역으로 내려가 실제 메모리가 어떻게 동작하는지 알아보겠습니다.
JVM의 Memory 구조
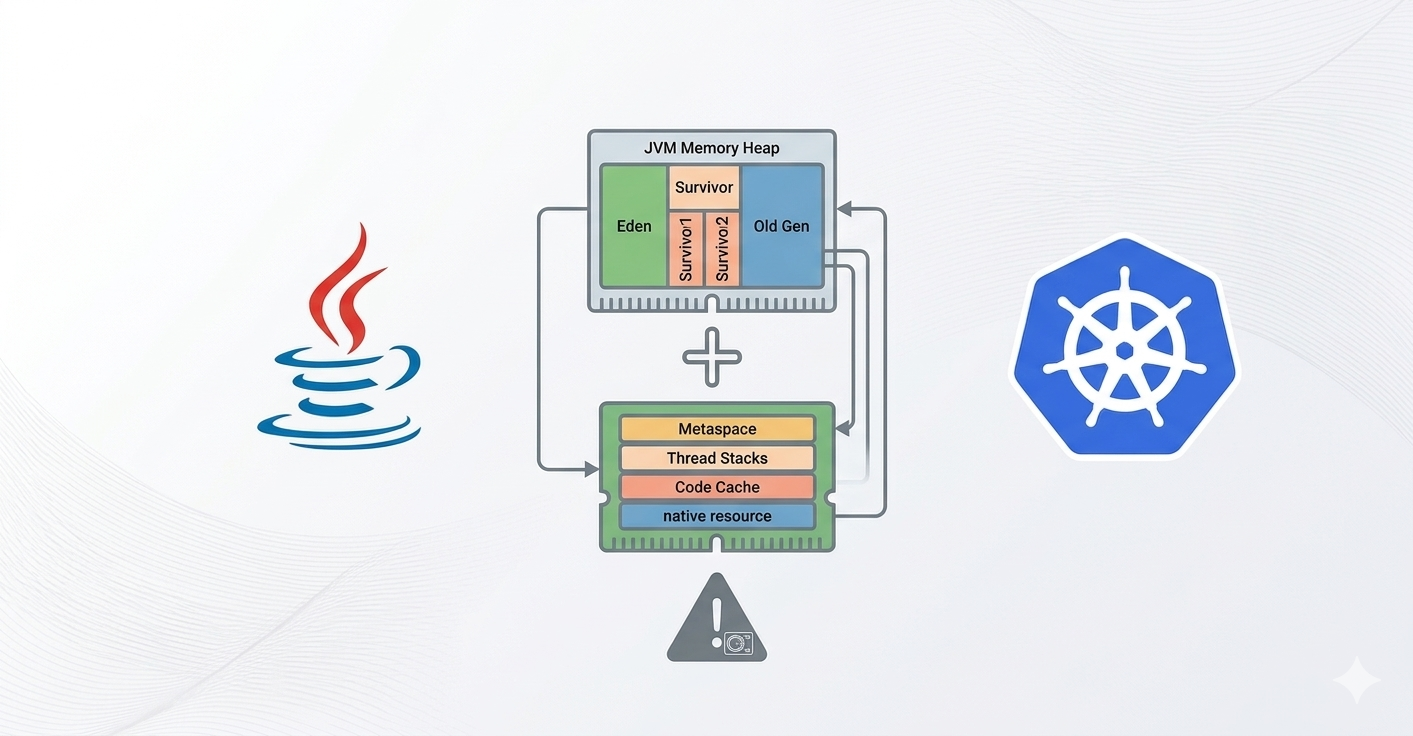
Pod 안에서 JVM이 차지하는 것
JVM은 Heap 영역과 별도로 여러 영역에서 메모리를 사용합니다. 그리고 이 전체 합산이 resources.limits.memory와 비교되어 Java Pod의 OOM을 결정합니다.
핵심은 Heap만 JVM이 관리한다는 점입니다. 나머지 영역은 모니터링 툴로도 쉽게 추적하기 어렵기 때문에, Heap은 정상으로 보이는데 Pod가 OOM으로 죽는 상황이 발생하기도 합니다.
MaxRAMPercentage 설정
JDK 10 이상부터는 UseContainerSupport 옵션이 기본적으로 활성화되어 JVM도 Pod의 limits를 인식합니다. 이를 바탕으로 MaxRAMPercentage를 통해 Heap 크기를 제어할 수 있습니다.
| 설정 | Heap (limits 1000Mi 기준) |
|---|---|
기본값 (25%) | 250Mi |
MaxRAMPercentage=65 | 650Mi |
MaxRAMPercentage=75 | 750Mi |
적용법
Dockerfile에 아래와 같이 JAVA_OPTS를 설정하고 Entrypoint에 넣어주면 됩니다.
1
2
3
4
5
ENV JAVA_OPTS="\
-XX:+UseContainerSupport \
-XX:InitialRAMPercentage=25.0 \
-XX:MaxRAMPercentage=75.0 \
-XX:+UseG1GC"
중요
MaxRAMPercentage는 Heap 상한만 제어합니다. Native Memory, Metaspace, Thread Stack은 이 설정과 무관하게 > 증가할 수 있습니다.
JVM Heap의 메모리 관리
실제 JVM이 관리하는 Heap은 모니터링 툴에서도 사용량을 관측할 수 있어 자주 Alert이 발생하곤 합니다.
Heap은 Java 객체들이 저장되는 곳으로 크게 Young Generation과 Old Generation으로 나뉘며, 각 영역은 별도의 GC가 관리합니다.
Minor GC의 Heap 관리
Minor GC는 Young Generation을 관리합니다.
개발자가 아래와 같이 Java 객체를 생성한다고 가정합니다.
1
String name = new String("hello");
Minor GC는 이 객체를 아래와 같은 방식으로 관리합니다.
name객체를 Eden(객체가 처음 태어나는 곳) 에 저장합니다.- Eden이 가득 차면 Minor GC가 사용하지 않는 객체를 정리합니다.
name의 참조가 살아있다면 Survivor(생존된 객체 대기 영역) 로 이동시킵니다.- 다음 GC에서 한 번 더 살아남으면 다른 Survivor 영역으로 이동시킵니다.
- 이를 반복하며 age가 증가합니다.
- age가 특정 수치에 도달하면 Old Generation으로 이동합니다.
Major GC의 Heap 관리
Major GC는 Old Generation을 관리합니다.
age 수치가 높은 객체 또는 static 객체들은 Old Generation에 저장되며, Major GC가 임계값에 따라 객체를 정리합니다.
다만 수GB에 달하는 용량을 정리하기 때문에 이 과정에서 STW(Stop The World) 가 발생합니다.
현대적인
-XX:+UseG1GC는 이를 짧게 여러 번 나누는 방식으로 개선합니다.
JVM의 나머지 영역
실제 객체가 저장되는 Heap 이외에도 Heap 밖 영역에서 메모리를 상당히 소모합니다.
- Metaspace: 클래스 메타데이터
- Thread Stack: 스레드마다 별도 할당
- Code Cache: JIT 컴파일된 코드 저장
- Native Memory: CXF, Netty 등 외부 라이브러리가 OS에 직접 할당
해당 영역들은 MaxRAMPercentage로 제어되지 않으며 Pod의 limits를 그대로 소모하기 때문에 OOM의 주요 원인이 될 수 있습니다.
ex1. CXF 프록시 미해제 - Native Memory 누수
1
2
3
4
5
6
7
8
MyService port = (MyService) factory.create();
try {
return port.getData(param);
} catch (Exception e) {
throw new RuntimeException(e);
}
// close() 없음 → Native Memory 누적
factory.create()가 실행되는 순간 JVM 외부에서 두 가지 자원이 열리게 됩니다.
TCP 소켓과 TLS 세션 버퍼, 이 두 자원은 모두 JVM의 Heap 영역이 아닌 Native Memory 영역의 자원으로 GC 대상이 아닙니다.
이 상태로 서비스가 운영되어도 초기에는 Pod의 메모리가 안정적으로 보이고 Heap 모니터링과 GC 동작도 정상으로 표시됩니다.
하지만 요청이 쌓일수록 Native Memory가 조용히 누적되며, 결과적으로 Pod를 OOM까지 발생시킬 수 있는 치명적인 Silent Failure가 될 수 있습니다.
정리
OOM은 단순히 메모리가 부족해서 발생하는 오류가 아닙니다.
Node, Pod, JVM, Native Memory까지 각 계층이 메모리를 어떻게 바라보는지 이해하지 못하면, Heap 모니터링이 정상임에도 Pod가 죽는 상황을 마주했을 때 원인을 찾기가 매우 어렵습니다.
이 글에서 다룬 내용을 정리하면 아래와 같습니다.
Node 레벨에서는 kubelet이 메모리 압박을 관리하며, limits 미설정 시 Node 전체가 위험해질 수 있습니다. JVM 은 Heap만 관리하며, MaxRAMPercentage로 Heap 상한을 제어할 수 있습니다. Heap 밖 영역(Metaspace, Native Memory 등)은 GC 대상이 아니며, 누수가 발생해도 모니터링에 잘 잡히지 않습니다. Native Memory 누수는 close() 미호출처럼 사소해 보이는 코드에서 시작되어 운영 중 조용히 축적됩니다. 실제 운영 환경에서 OOM을 마주했을 때 이 글이 조금이나마 도움이 되었으면 합니다.